The Pre-Development Phase: How to Avoid Mistakes that May Cost You a Fortune


When someone wants to emphasize the importance of the first step in doing something, we often hear them say something like, “It’s important to build a strong foundation.” But if you look at that plan more closely, it’s easy to see that the foundation isn’t the very beginning: before laying the cornerstone, and even before digging the construction pit, many preliminary decisions must be made. You should look around, decide what exactly you want to build, then determine the sequence of actions, and so on. Moreover, when making all these decisions, you should take into account further prospects – in other words, the future of your project.
Software development works according to similar rules. Before actually coding, you have to make strategic decisions regarding the product’s architecture, design, how it works with data, etc. All this happens in the initial stages.
To help you sort this out, let’s focus on the Pre-Development stage, define its place in the software development process, and consider the points that are especially important to pay attention to so that your project can move ahead smoothly and without high-cost mistakes.
Pre-Development Stage: What’s in It?
As you can learn from the article that describes Software Development Life-Cycle, the Pre-Development phase follows the Discovery phase and precedes the Development phase.
Pre-Development Vs. Discovery: What’s the Difference?
The interaction of planning, analysis, and project structure development as a whole occurs in both of these phases. However, there are differences.
- The Discovery phase is a “strength test” of your product idea. The clarification of requirements can be considered as its core, especially from a business point of view, i.e., checking the desirability of developing a product with specified characteristics in a competitive environment and a preliminary estimate of the budget and resources required to make it happen.
- The Pre-Development phase (i.e. preliminary development) is more about the developers’ perspective. This includes deploying servers, setting up tools, API design, defining test strategy and a project roadmap, etc.
Like preparing construction blueprints that you can hand over to different contractors, the Discovery phase can act as a separate service and be carried out even before you’ve decided to cooperate with a certain vendor. Ideally, though, these two phases flow smoothly into each other.
Who’s Involved in the Pre-Development Process?
Since the initial stages of project development largely determine the future “room for maneuvering”, it’s crucial here to listen carefully to the recommendations of an experienced vendor and involve highly qualified developers. You shouldn’t skimp on paying for senior-level workers because mistakes can be very costly (to the extent of having to rework the project).
On the other hand, you may need to connect with some specialists only once, because there’s no need for constant participation in the project from their side.
| Role Name | Responsibility | Involvement |
| Business Analyst | Provides business analysis and appropriate outcomes, e.g., the Project Estimate. | one-time |
| Tech Lead |
|
process owner |
| Project Manager | Coordinates team organizational activities such as Backlog fulfillment, communication with the client, etc. | full-time |
| QA | Is responsible for project quality, preparing testing documentation, and performing software testing. | full-time |
| Solution Architect |
|
full-time |
| UX/UI Engineer |
|
full-time |
Depending on the size and structure of a particular company, the composition and names of the SDLC roles might vary slightly. For example, the Team Leader can assume the Tech Leader role. However, practice shows that you shouldn’t get carried away with the combination of roles, and certainly shouldn’t omit the tasks for which an appropriate specialist is required.
The Outcomes of the Pre-Development Phase
After completing the pre-implementation stage, you should be fully prepared for the Development phase and able to provide it with the needed inputs. The full list might vary, but here are the major points to pay attention to:
- Product Backlog, i.e., a scope of forthcoming tasks that will be performed according to priority.
- CI/CD workflow: tests, build, deploy.
- API design with a short specification of all API endpoints required for the new application.
- Design artifacts including
– a User Flow (the order of actions that users follow to achieve their goal when using the product);
– a Wireframe (black and white images without any app data that represent not the app design, but what elements should be situated on the page);
– a Mockup (the early version of the product visual design that represents not only the elements on the pages but how the data will be shown to users);
– and a Prototype (live presentation of your application that imitates the app behavior like on an interactive storyboard and could be shown to investors or end-user for gathering their feedback). - BPMN Diagram of the main flow (Business Process Modelling Diagram).
- An updated Test Strategy (a document that describes the testing approach of the specific software product).
- Components structure (formed in Jira).
- Configured development and beta environments.
Note that, as mentioned above, the software vendor might change after the Discovery phase is completed. In this case, the chosen solutions might be adjusted again according to the expertise of the new team. For example, they might advise you to reconsider your decision about choosing the product architecture. We’ll discuss this in more detail below.
Mistakes to Avoid at the Pre-Development Stage
The main mistake would be underestimating the preparatory work. This is similar to the principle attributed to Napoleon: get involved in that battle, and see what happens next.
However, a different principle applies in construction: you can’t just demolish a building after you understand how it should have been built. Rather, you can, but this means additional money and time.
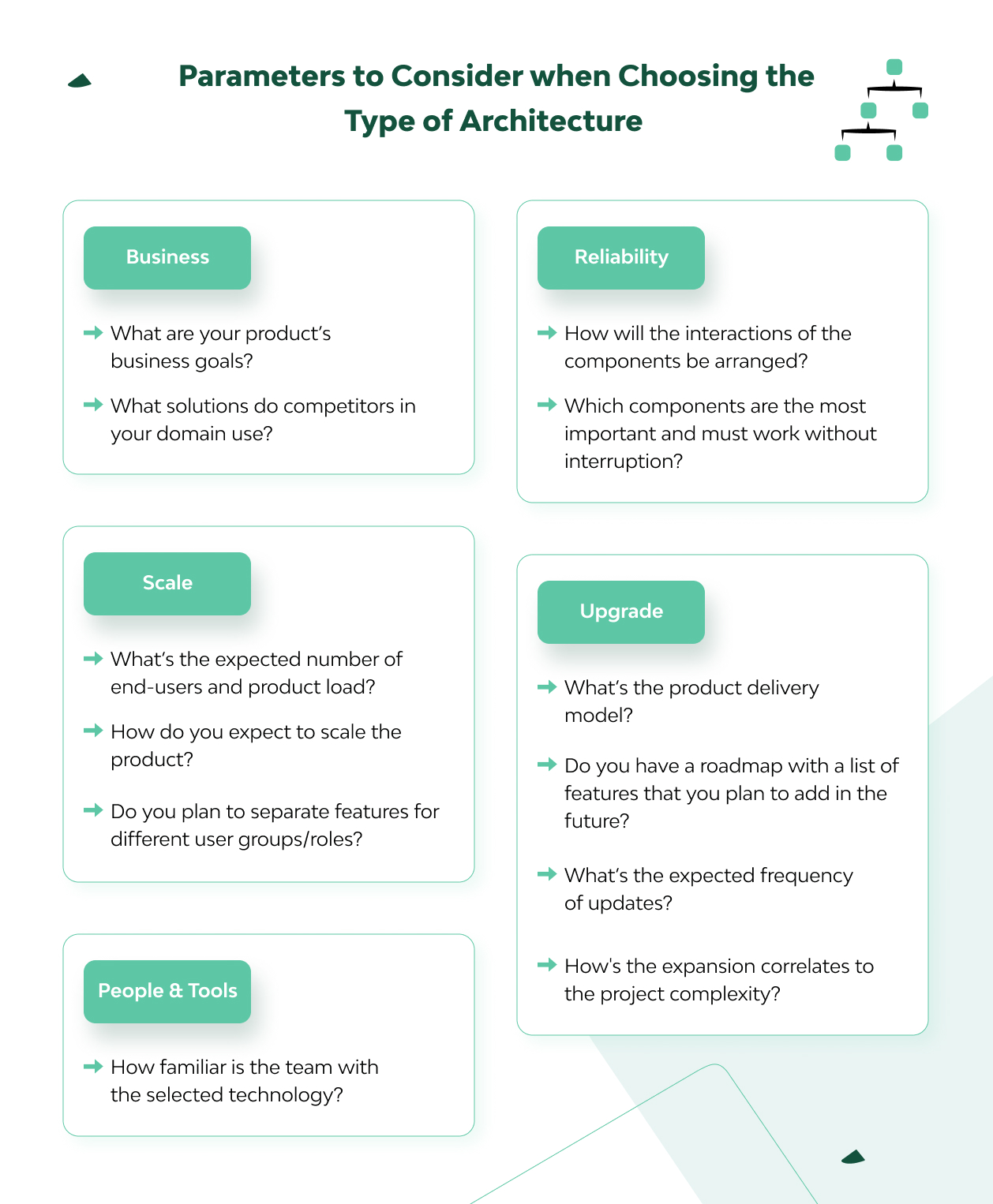
Equally, in software development, you inevitably have to start by defining the logic of user actions, choosing the type of architecture, and the API design. You should keep in mind many important parameters such as the expected number of users and the load on the product, the correct configuration using suitable frameworks, testing capabilities, performance, scalability, etc.
Generally, architectural decisions are made during the Discovery phase. Then the process configuration and task prioritization are passed to Pre-Development. In practice, however, it’s usually the vendor implementing the project that makes the final adjustments at the Pre-Development phase.
And since the architecture choice will dictate further possibilities, boundaries, and the mainstream of your project development, this step should be taken seriously.
More on Architecture: How to Choose the Right One
When choosing architecture, developers are often tempted to foresee all possible situations in advance. By doing so, they run the risk of not only overcomplicating the architecture but also introducing errors into the project. And, you know, reality will still make its own adjustments that you didn’t calculate.
Usually, the best way is to start small but have well-thought-out functionality that can be scaled as needed. A good tip is to take a close look at the processes in your business domain in order to model their logic as accurately as possible.
But at the same time, it’s important to abstract to the necessary degree from the organizational structure of both your company and the vendor’s company to avoid a pitfall that Conway’s Law warns about: “Any organization that designs a system will produce a design whose structure is a copy of the organization’s communication structure.” (Otherwise, you can quietly introduce old boundaries into the new design.)
Types of Architecture and Cases When It’s Most Appropriate
Some architectures are more famous than others. But it’s not about just fashion or what you might have seen from your neighbors. Instead, the project itself and the gathered requirements should dictate your choice of architecture. Here, everything is individual.
1. Layered Architecture (a.k.a. N-Tier Architecture)
This is perhaps the most widely known layered architecture concept. It’s found in most Java EE applications. Here, the components are organized into horizontal layers. (Their number and order may vary depending on the size and purpose of the application.)
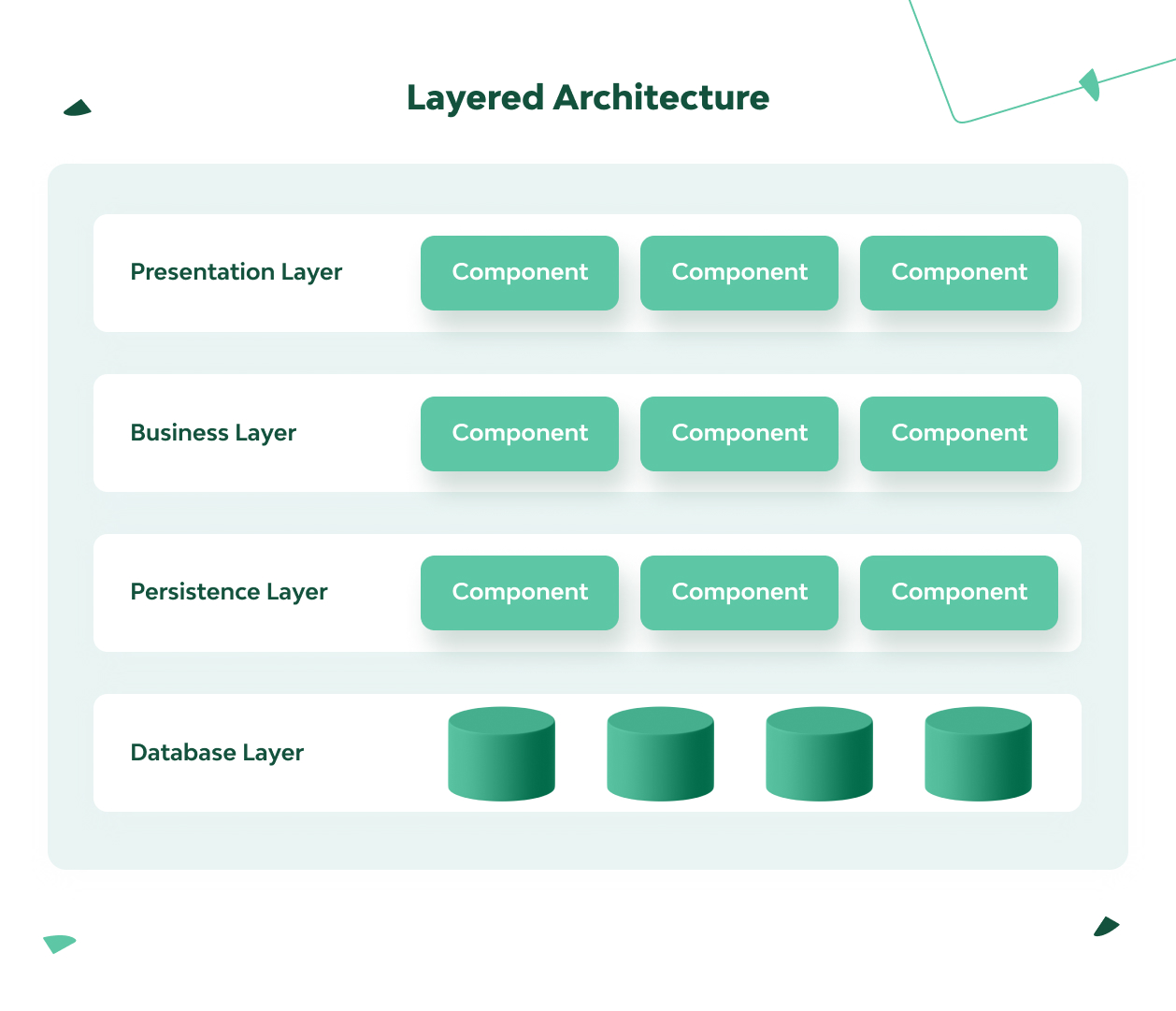
Each layer has a specific role in the application, such as storing data, processing requests, or presenting the user interface. It’s important that adjacent layers can exchange data in a suitable format without caring about the tasks of each other. For example, the presentation tier should only display customer data, not process it. At the same time, data cannot flow from one layer to another by bypassing the layers between them.
The distribution of tasks and autonomy of layers helps simplify the pre-development, development, testing, management, and maintenance of applications in a layered architecture due to well-defined component interfaces and limited component scope.
Pros and Cons:
✔ It’s easy to start. Generally, if you don’t know where to start, it makes sense to start with a layered architecture.
✔ A large choice of frameworks is available.
✘ Expanding functionality isn’t always easy because, as a rule, you have to use several layers to implement new features.
✘ It’s relatively difficult to achieve high performance.
✘ Achieving scalability is challenging.
Note: The wide popularity of layered architecture is due to the fact that it’s a convenient default option for a project. Usually, if you don’t know where to start, it would help if you start with it. Due to the isolation of the layers, any of them is quite easy to modify or even completely replace if necessary.
2. Event-Driven Architecture
Event-driven architecture uses an asynchronous operating principle, which is a good choice when building highly scalable software products.
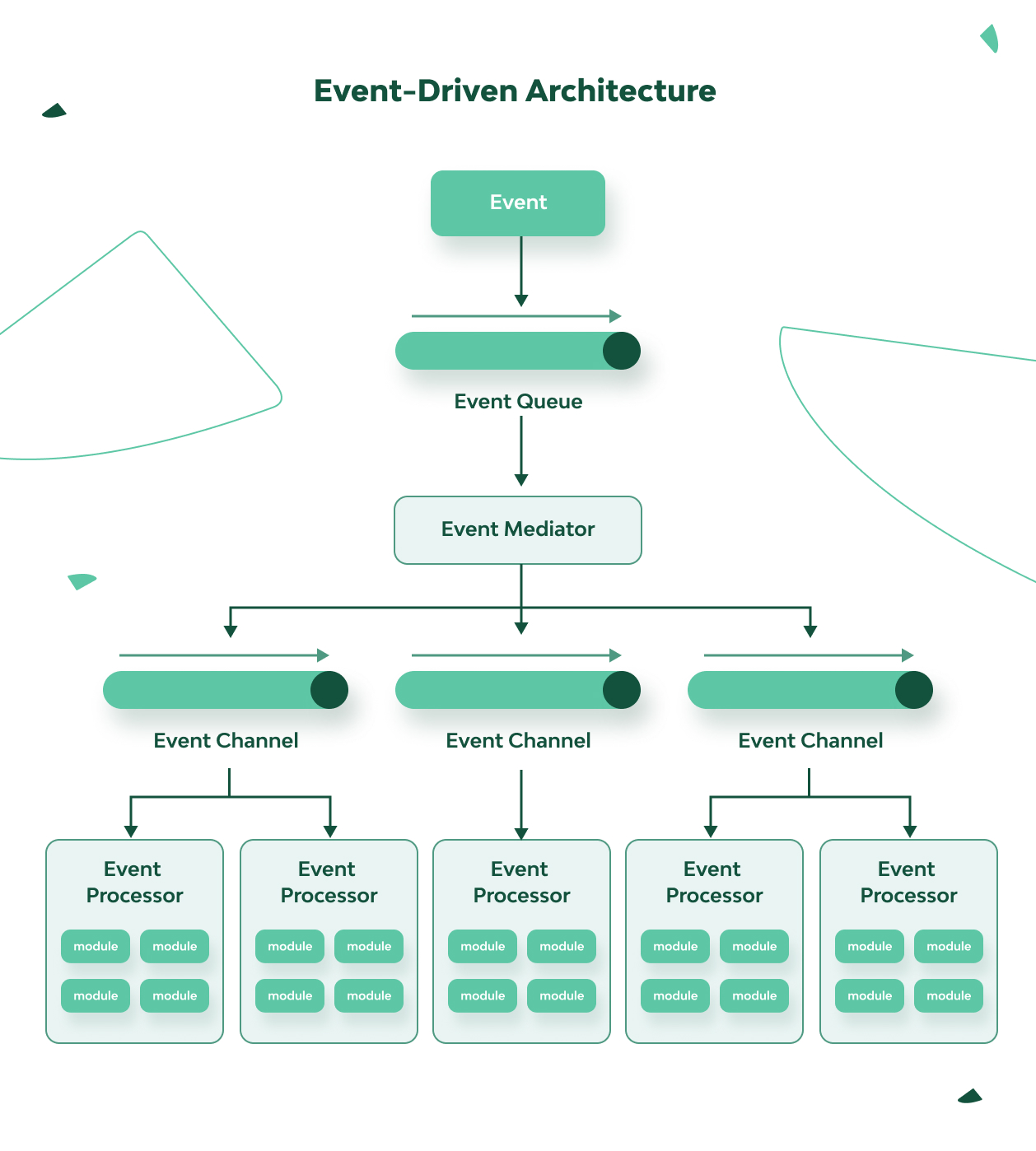
This architecture focuses on the event queue. Various event processors are subscribed to these events and do their part of the overall work asynchronously. For example, in an online store, when an event comes in the form of an order, separately prescribed processors can handle the reservation of goods in the warehouse, invoicing, shipping, and other subtasks. In this pattern, the channel of initial events can be split into smaller channels that, in turn, contain processing events. Another implementation method is to distribute the event flow across the processor components in a chain-like fashion (suitable for less-complex products).
Because the event-driven architecture is asynchronous, it’s relatively difficult to implement. Here, you need to think carefully about which events can be executed independently to avoid conflicts.
Pros and Cons:
✔ Expansion of the functionality is easy, because it usually comes down to adding new processors that can be connected independently.
✔ Testing is easy.
✔ Scalability isn’t difficult, and we can vary the technologies used in different processors.
✔ High performance can be achieved.
✘ Despite its apparent simplicity, the architecture is difficult to design.
✘ Identifying problems can be difficult (due to a large number of interacting processes).
✘ It’s difficult to ensure eventual consistency (due to asynchronous data changes that can be delayed).
Note: Different types of architecture can be combined. For example, you can make one of the event processors layered or, conversely, build one of the layers using event-driven architecture.
3. Microkernel Architecture (a.k.a., Plug-In Architecture)
The microkernel architecture is generally the first choice for building product-based applications. It allows you to add additional features as plug-ins to the core application, which provides extensibility as well as separation of different functions.
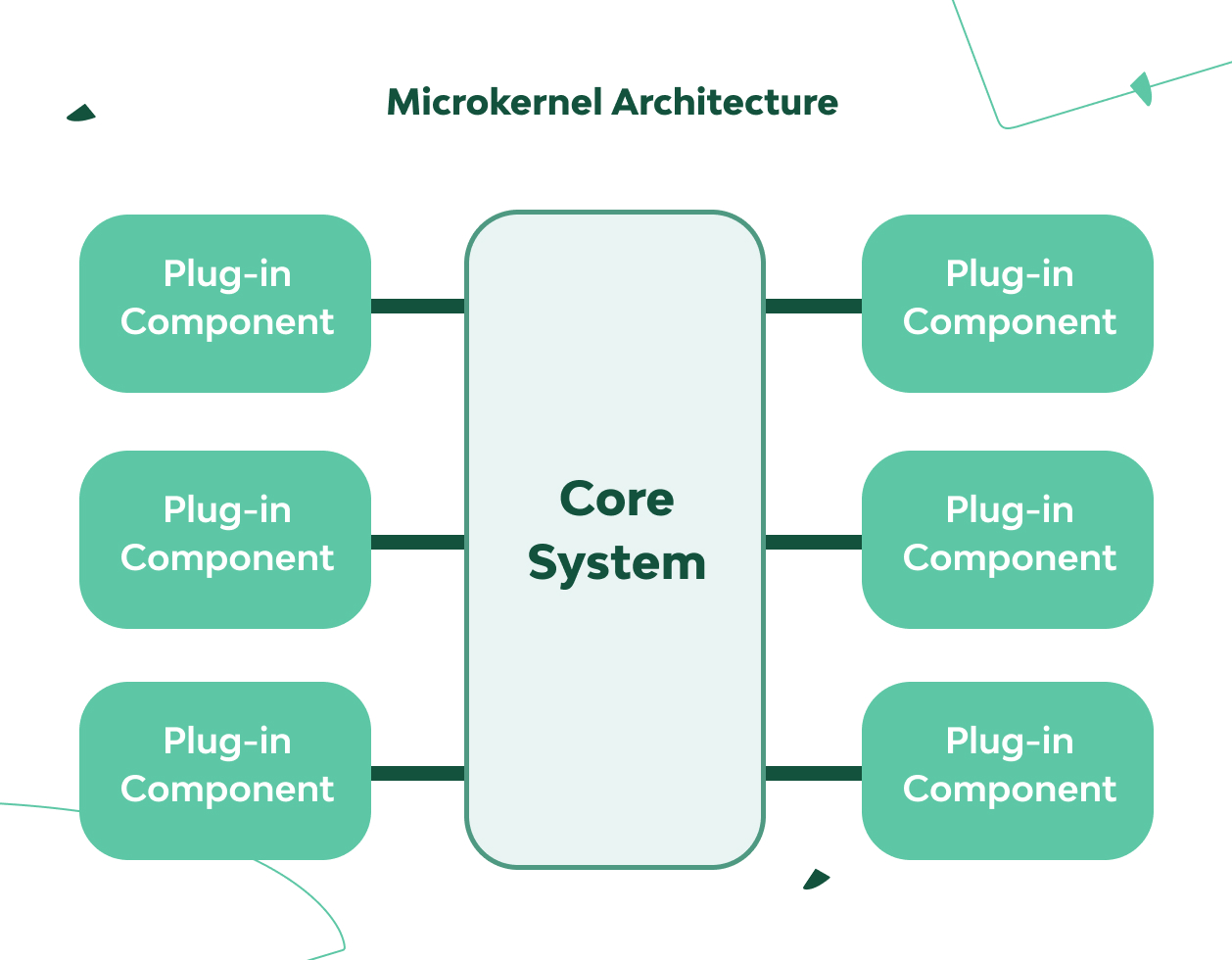
This architecture uses two types of components: a core system, which contains only minimal functionality, and stand-alone plug-in modules with additional functionality. Thus, it becomes possible to choose only the necessary functions for connection or to customize the application for specialized needs. Also, it’s convenient if you want to control user access to various functions.
Plug-ins can be connected in various ways, be completely independent, or require other modules to be installed. But it’s important here to minimize data exchange between modules to avoid dependency issues.
Pros and Cons:
✔ It’s easy to extend functionality with additional plug-ins.
+/- Performance can vary in different cases.
+/- Scalability can vary in different cases, depending on how the kernel is written and how the plugins interact.
✘ It’s difficult to design (since the core system determines the format of further interactions.)
Note: This type of architecture isn’t common in web development. A simple example of such an architecture would be various IDEs, where the basic version is usually a text editor, but one for which you can get a convenient development tool by connecting various plug-ins with additional features.
4. Microservice Architecture
The popularity of microservice architecture is growing because it arose to solve the well-known problems inherent in monolithic applications (cumbersome deployment) and service-oriented architectures (excessive complexity).
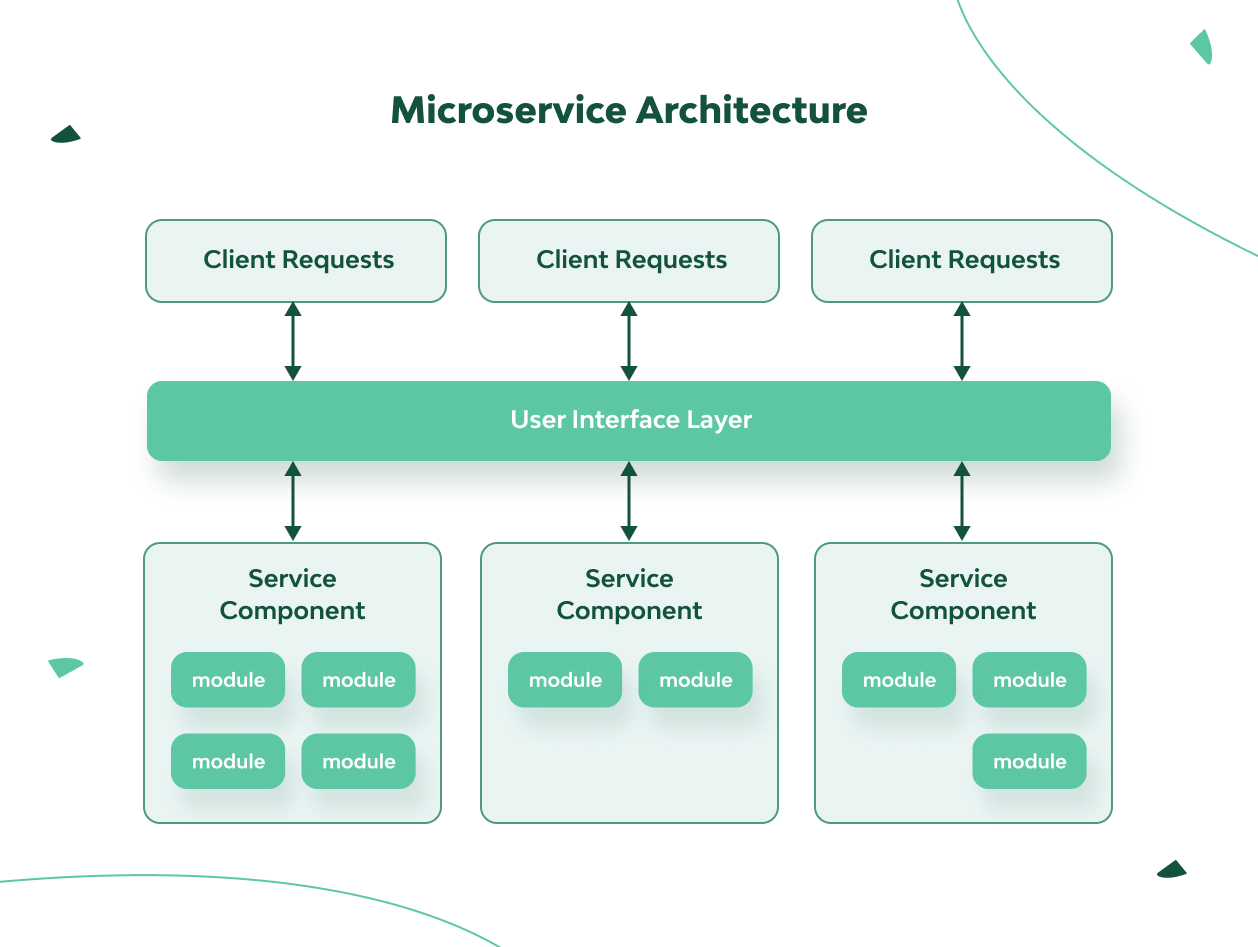
Each component of the microservice architecture is deployed as an independent unit and is completely separate from the others. The components are accessible via the remote access protocol.
This distributed architecture contributes to increased scalability, ease of deployment, and continuous delivery. On the other hand, it can be more difficult to achieve coordinated functionality due to a high degree of application and component decoupling within your application. Hence, there’s a high probability that the functionality of various components will be largely duplicated to preserve the independence of the components. Also, it’s difficult to maintain consistent processing of a single transaction by different service components.
Pros and Cons:
✔ The functionality is easy to expand (if the interface layer is written correctly).
✔ Performance can be high (thanks to component optimization).
✔ Scalability isn’t very difficult.
+/- Testing one microservice is easy, but testing the interaction of many microservices is difficult.
✘ It’s difficult to design.
Note: Like event-driven architecture, microservices hide complexity behind seeming simplicity. Here, you need to properly divide closely related services, carefully consider the interface layer, ensure data security, permissions, etc.
A Word about Difficulties and Other Architecture Approaches
There’s no reason to say that any one of the architectures is the answer to every question. Why else would you need so many different answers? The aforementioned pros and cons can manifest themselves on different scales. Much depends on the specific implementation.
There’s always complexity. But in different architectures, this complexity can look different:
- With Layered Architecture, data conversion from layer to layer is important.
- With Event-Driven Architecture, you should take into account Eventual Consistency.
- With Microkernel Architecture, the requirements for the kernel architecture are increased.
- With Microservice Architecture, the interface (communication) layer between services is the most responsible.
Of course, we’ve come across many other approaches to software architecture. (For some interesting examples, refer to The Clean Architecture by Robert Martin.) But on closer inspection, many of them turn out to be author’s variations on familiar themes that use similar principles. Often, it’s more about placing emphasis and going deeper into some architectural “framework.” In any case, when choosing an architecture, you must first take into account all the tasks that a specific project sets out for you.
However, one more checklist is never superfluous.
Haste Makes Waste
It’s necessary to clearly understand that the decisions made in the Pre-Development phase will become the basis for the further development of the product. Therefore, in the future, even seemingly minor changes in the interface, for example, might require serious changes in the data structure, in which case you again will need to spend time/money and involve qualified people.
When deciding on a project architecture, much depends on developers’ professional experience and background. As it’s the time when the scope of the future project is being defined, the correct systematic approach shouldn’t be neglected. Definitely, it makes sense to listen to the vendor’s recommendations and not overlook important details. A good idea is to find a vendor who offers not just “hands-on” but expertise in building complex solutions for business needs.
Visit our case studies page to learn more about DjangoStars as a software vendor. To discuss cooperation, fill out the get in touch form.
- Are the pre-project phase and pre-development the same thing?
- Both phases are preliminary, but there is a difference. When preparing for a project, the discovery phase can be considered a “strength test” of the product idea. Its core is the clarification of requirements, especially from a business point of view (including the product competitiveness and the resources needed for its development). The pre-development phase is more about the developers’ perspective. This includes deploying servers, setting up tools, API design, defining test strategy and a project roadmap, etc.
- Why is it risky to omit the pre-development phase?
- It’s necessary to clearly understand that the decisions made in the Pre-Development phase will become the basis for the further development of the product. Therefore, in the future, even seemingly minor changes in the interface, for example, might require serious changes in the data structure, in which case you again will need to spend time/money and involve qualified people.
- Who participates in the software development process at the pre-development stage?
- Business Analyst
- Tech Lead
- Project Manager
- QA
- Solution Architect
- UX/UI Engineer
Don't skimp on paying senior-level workers because mistakes can be costly. On the other hand, you may need to connect with some specialists only once because there's no need for constant participation in the project from their side.
- What is your company's experience in performing pre-development?
- The pre-development phase is the stage that precedes the development of software products in DjangoStars. To conduct it, we engage experienced business analysts, project managers, engineers, designers, and solution architects. Our team has sharp tech skills and versatile knowledge of clients' domains and target locations trusted by Fortune 500 and Y Combinator.
Hire experienced developers to build your next project with DjangoStars







