How to Develop RAG Question-Answering System: Examples and Use Cases


Question-answering systems have enhanced user interactions with accurate and timely information. This time, we’ll explore how to develop a RAG question answering system with Python. While this guide focuses on the core Python implementation, the same RAG pattern generalizes to enterprise scenarios—including generative ai in supply chain, industrial manufacturing, and financial services—so you can adapt the steps to your own domain data without altering the fundamentals. This leverages Natural Language Processing (NLP) and machine learning advancements to improve these systems, providing more contextually aware and precise responses.
By the end of this article, you will know:
- The basics of Question and Answer applications
- Overview of RAG (Retrieval-Augmented Generation)
- How to implement RAG without LangChain
- Practical code examples
- Case Study from DjangoStars
Whether you’re looking to build a new question-answering system for a chatbot or enhance an existing project with advanced AI capabilities, this tutorial will provide you with the knowledge and tools necessary to navigate the complexities of these technologies. You will also discover how AI tools helped DjangoStars transform Illumidesk into a robust system.
Overview of Q&A Applications
Question and Answer (Q&A) applications are powerful tools that streamline how we interact with information, enabling users to receive quick and precise answers. These applications integrate complex workflows and modern technologies, making them incredibly efficient for handling various tasks across multiple domains.
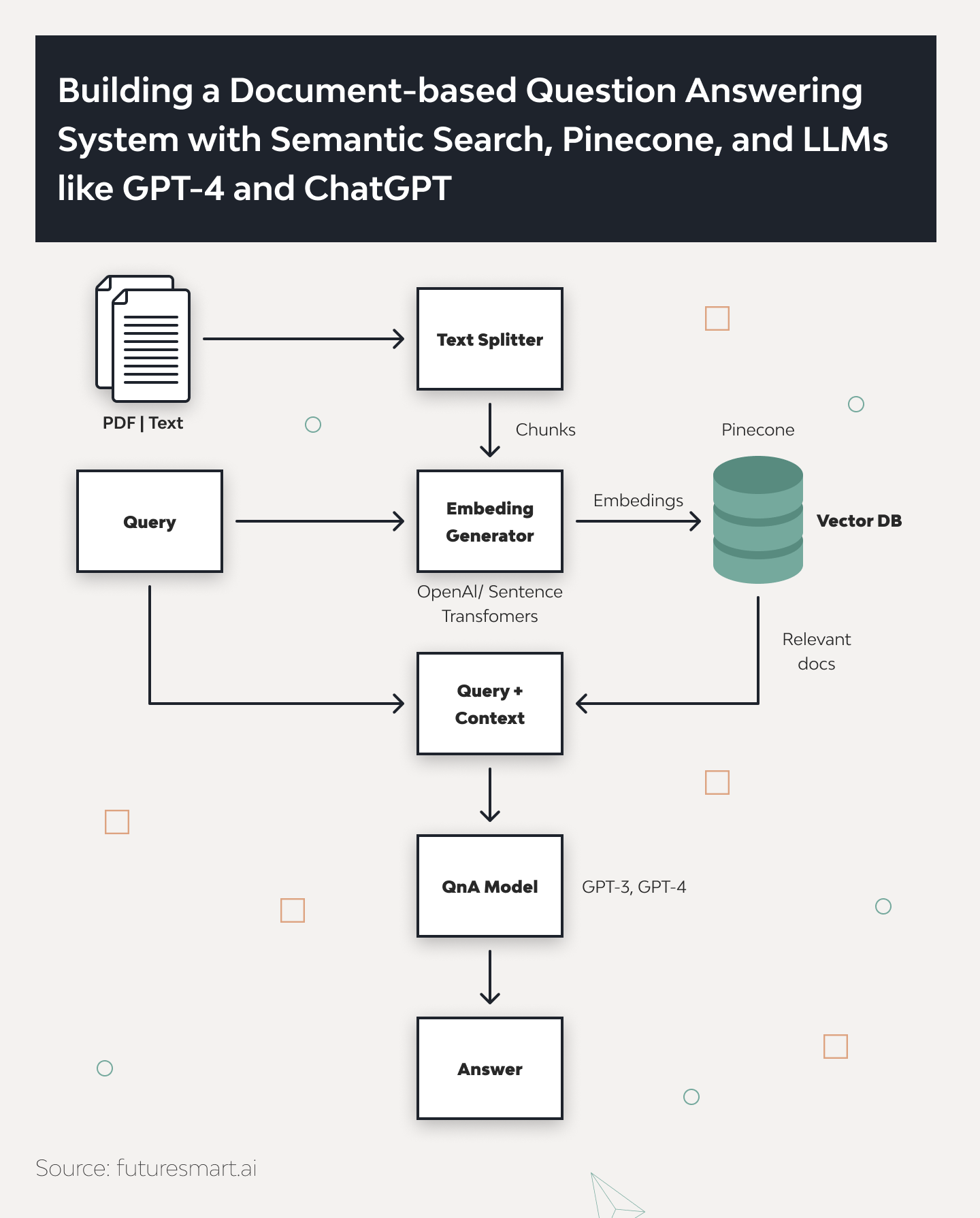
Detailed Workflow of Q&A Applications
Here’s a closer look at how a typical RAG question answering with Python application operates, utilizing advanced components for processing and retrieving information:
- Document Loaders. The initial step involves loading the documents from which you need answers. These documents are then prepared for processing, often converting into a format suitable for analysis.
- Text Splitters. The documents are split into manageable chunks. This helps organize the data better and optimize the storage and retrieval processes.
- Vector Storage. Once the documents are prepared, their text is converted into vector embeddings. These embeddings are then stored in a vector database, such as Pinecone. This database is designed to handle large volumes of data and retrieve them with minimal latency, enhancing the application’s performance.
- Document Retrieval. When a user submits a query, the system uses similarity search techniques to find and retrieve the most relevant document segments from the vector database. This is crucial for having accurate and contextually relevant conversations.
- Model Output. Finally, the retrieved texts are used to generate a precise answer to the user’s query. This response is based on the context of the user’s initial question and the information retrieved from the database.
In addition to Pinecone, we can use an SQL database for vector storage. One example is the PGvector plugin for Postgres. These databases are similar to ElasticSearch, where we store and search by key-value pairs. This makes searching more efficient as it involves searching for pairs of ‘key = vector’ and ‘value = text’.
Advantages of Custom Q&A Applications
Custom-built Q&A applications offer several significant advantages over traditional model methods:
- Context-Specific Answers. They provide answers that match the query’s context, resulting in more relevant and valuable responses.
- Adaptability. These applications can continuously adapt to new documents and data, expanding their knowledge base and accuracy.
- Cost-Efficiency. Since there is no need for ongoing model training, these applications can be more cost-effective while still delivering high-quality outputs.
- Precision. By leveraging advanced vector databases and retrieval methods, custom Q&A applications can offer more precise answers than general Q&A models.
Retrieval Augmented Generation (RAG) for Question-answering
RAG combines the strengths of retrieval-based and generative systems. This hybrid approach allows for more accurate, informed, and context-rich responses in Q&A applications.
How Does Retrieval Augmented Generation with Python Work?
The RAG framework operates through a two-step process:
- Retrieval Phase. Initially, the system uses a retrieval component called a “retriever” to query a vast knowledge base. It can be a database, a document collection, or a web. The retriever identifies a subset of documents relevant to the user’s question. This step ensures that the information used to generate answers is relevant and precise.
- Generation Phase. Following the retrieval, the generative component, known as the “generator,” takes over. It crafts a response based on the original question and the information extracted during retrieval. Unlike traditional models that generate answers based solely on pre-trained knowledge, RAG can dynamically incorporate new, external data for each query.
Here’s a simple illustration of implementation a RAG system for a Q&A application:
- Data Retrieval. Start by configuring a document loader to fetch and prepare the documents. These documents are then processed into a suitable format for the retrieval phase, often using techniques like text splitting to enhance search efficiency.
- Vector Embedding. The documents are converted into vector embeddings using language models, which help map the textual information into a numerical space that machines can understand and compare.
- Similarity Search. Using similarity search techniques, the embedding of a given user query is compared against the document embeddings. This helps find the most relevant text within the document corpus.
- Answer Generation. The generator combines the retrieved text with the original query to create a coherent and contextually relevant answer.
Here is an example of setting up a semantic search pipeline with RAG to create a system that answers questions based on a set of documents:
def rag_answer(question, documents):
query_embedding = embed(question)
similar_docs = retrieve_similar_documents(query_embedding, documents)
retrieved_text = " ".join([doc.text for doc in similar_docs])
answer = generate_answer(question, retrieved_text)
return answerIn this example, embed converts the question into a vector, retrieve_similar_documents searches for the most relevant documents, and generate_answer combines the query and retrieved texts to produce the final response.
Understanding RAG without Langchain
For those looking for retrieval-augmented generation techniques in Python without the Langchain library, the process can be distilled into several specific tasks: setting up a document retriever, generating embeddings, querying these embeddings, and then using the results to inform a generative model for answer generation. Here, we’ll focus on a more direct approach using available tools.
Step 1. Set Up the Retriever
You need a mechanism to retrieve relevant documents based on a query. This involves:
- Embedding Documents. Convert text documents into numerical vectors using transformer-based models like BERT, available through the Hugging Face transformers library.
- Indexing Vectors. An indexing library such as FAISS can be used to organize these embeddings efficiently for rapid retrieval. You’ll find a full code sample after the last step.
Step 2. Retrieve Documents
For a given query, convert it into an embedding and use your FAISS index to find the most relevant document embeddings.
def retrieve_documents(query, tokenizer, model, index, documents, k=5):
query_inputs = tokenizer(query, return_tensors='pt', truncation=True, max_length=512)
query_outputs = model(**query_inputs)
query_embedding = query_outputs.last_hidden_state.mean(dim=1).detach().numpy()
_, indices = index.search(query_embedding, k)
return [documents[idx] for idx in indices[0]]Step 3. Generate Answers
Use the retrieved documents to generate an answer. This can be done with an OpenAI generative model, where you format the input to include both the query and the context provided by the retrieved documents.
import openai
def generate_answer(query, retrieved_docs):
context = ' '.join(retrieved_docs)
prompt = f"Based on the following information: {context}, answer the question: {query}"
response = openai.Completion.create(
engine="davinci",
prompt=prompt,
max_tokens=150
)
return response.choices[0].text.strip()Combining the Components for a RAG System:
def answer_question(question):
retrieved_docs = retrieve_documents(question, tokenizer, model, index, documents, k=5)
answer = generate_answer(question, retrieved_docs)
return answerHere is an example with transformers and FAISS index where we also install a library for the base vectors and use custom models:
from transformers import AutoModel, AutoTokenizer
import torch
import faiss
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
model = AutoModel.from_pretrained('bert-base-uncased')
# 'documents' is a list of document texts
embeddings = []
for doc in documents:
inputs = tokenizer(doc, return_tensors='pt', truncation=True, max_length=512)
outputs = model(**inputs)
embeddings.append(outputs.last_hidden_state.mean(dim=1).detach().numpy())
# Convert list of np.arrays to a single np.array
embeddings = np.vstack(embeddings)
# Create and train FAISS index
index = faiss.IndexFlatL2(embeddings.shape[1])
index.add(embeddings)This setup explains using RAG for question-answering systems without specific libraries like Langchain. By understanding and controlling each part of the process, you gain the flexibility to customize and optimize your question-answering system to fit your specific needs better.
Easy Example of Using RAG with Python and OpenAI
Retrieval-augmented generative QA with OpenAI combines the power of search and language generation to provide nuanced answers based on extensive text corpora. This example will demonstrate a straightforward RAG implementation using Python and the OpenAI API to process and extract information from large text data.
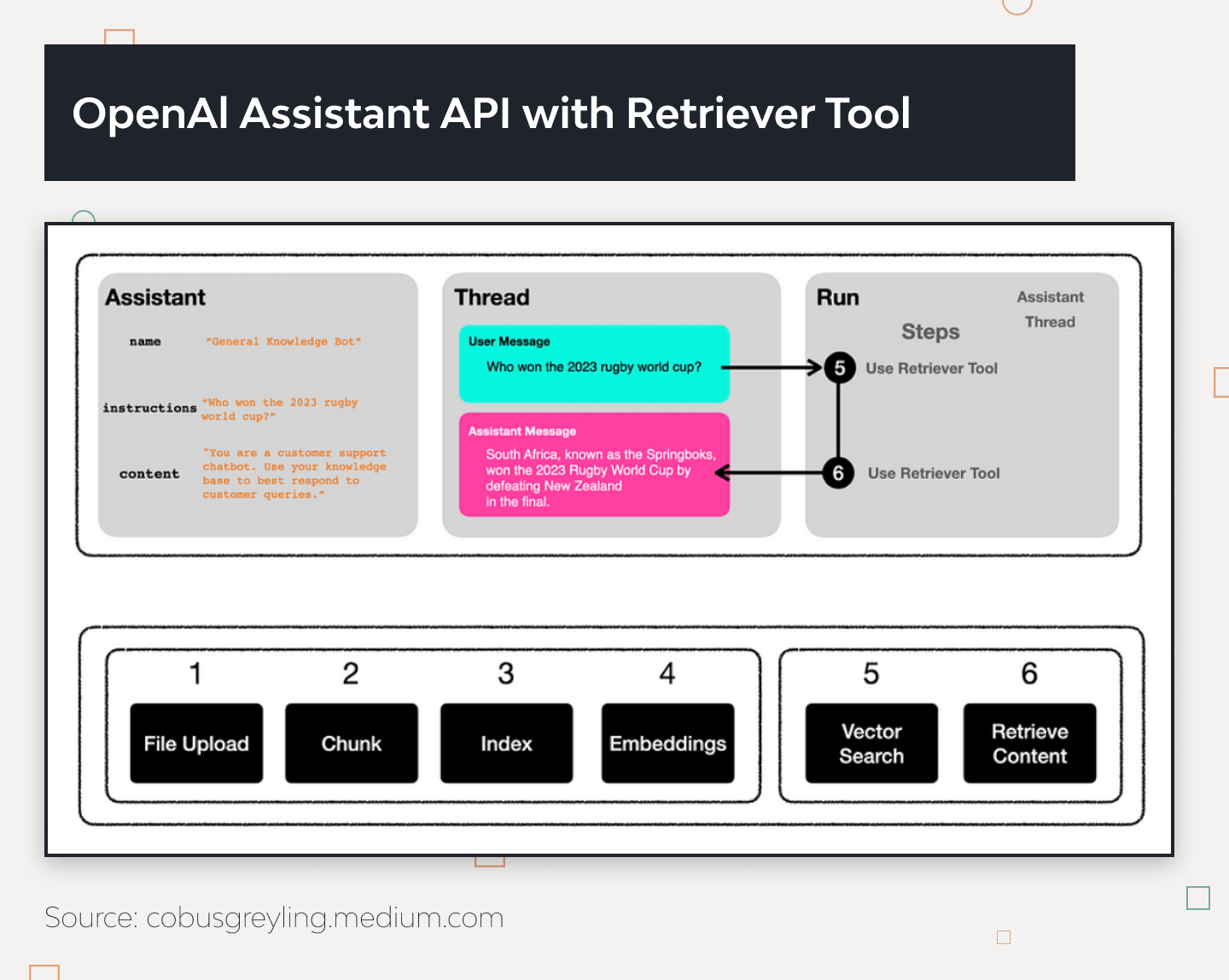
Step 0: Preparation of Text Data
Start with a substantial amount of text data. For this example, let’s take a long text about what artificial intelligence is.
long_text = """[Insert some long text about AI here]"""Step 1: Text Segmentation
Divide the text into manageable segments. This helps handle large texts and improves the efficiency of embedding and retrieval processes.
def split_text_into_chunks(text, chunk_size=200):
return [text[i:i + chunk_size] for i in range(0, len(text), chunk_size)]
text_chunks = split_text_into_chunks(long_text, 200)Step 2: Generating Embeddings for Text Chunks
Use OpenAI’s API to generate embeddings for each text chunk. Store these embeddings in a dictionary with embeddings as keys and text chunks as values.
import requests
headers = {
"Authorization": f"Bearer YOUR_OPENAI_API_KEY",
"Content-Type": "application/json",
}
embeddings_dict = {}
for chunk in text_chunks:
response = requests.post(
"https://api.openai.com/v1/embeddings",
headers=headers,
json={"input": chunk, "model": "text-embedding-ada-001"}
)
if response.status_code == 200:
embedding = response.json()['data'][0]['embedding']
embeddings_dict[tuple(embedding)] = chunkStep 3: Question Embedding
Embed the question using the same model to ensure compatibility with the embeddings in the database.
question = "What is artificial intelligence?"
response = requests.post(
"https://api.openai.com/v1/embeddings",
headers=headers,
json={"input": question, "model": "text-embedding-ada-001"}
)
query_vector = response.json()['data'][0]['embedding']Step 4: Retrieving Relevant Text Segments
Compare the question’s embedding with the embeddings in the database using cosine similarity to find the most relevant segments.
from scipy.spatial.distance import cosine
def find_top_k_matches(query_vector, embeddings_dict, k=3):
similarity_scores = {1 - cosine(query_vector, vec): text for vec, text in embeddings_dict.items()}
return dict(sorted(similarity_scores.items(), key=lambda item: item[0], reverse=True)[:k])
top_matches = find_top_k_matches(query_vector, embeddings_dict)Step 5: Constructing the Final Query with Relevant Contexts
Concatenate the question with the top retrieved contexts to create a rich prompt for the language model.
context = " ".join(top_matches.values())
final_prompt = f"Question: {question}\nContext: {context}"Step 6: Generating the Answer
Send the final prompt to a language model like GPT-3 or GPT-4 to generate an insightful answer.
response = requests.post(
"https://api.openai.com/v1/chat/completions",
headers=headers,
json={"model": "gpt-3.5-turbo", "messages": [{"role": "user", "content": final_prompt}]}
)
answer = response.json()['choices'][0]['message']['content']
print("Generated Answer:", answer)This simple example showcases how to use Python and OpenAI’s API for a RAG implementation.
Technical Transformation of Illumidesk with DjangoStars
In early 2022, DjangoStars took on the challenge of revamping Illumidesk, an edtech platform struggling with scalability and functionality limits. Our goal was to transform it into a more robust and efficient system.
We started by redesigning the platform’s architecture to handle growing user demands more effectively. We integrated new tools for managing and analyzing educational content to improve efficiency. This made the system not only smoother but also more insightful.
A key upgrade was integrating AI tools like ChatGPT (one of the advanced LLMs), which automated many course creation and grading tasks. This move significantly reduced the manual effort required from educators, making their work easier and more accurate.
Our team, including backend and frontend engineers, QA specialists, a product designer, a project manager, and a DevOps engineer, relied on a solid tech stack centered around Python, Django, and FastAPI. This setup ensured the platform could manage more traffic and data without a hitch.
Thanks to these upgrades, Illumidesk is now a more scalable and stable platform, ready to meet the diverse needs of educational institutions today.
Conclusion
Retrieval Augmented Generation presents a sophisticated method of handling Q&A tasks, blending retrieval’s accuracy with the flexibility of generative models. This approach enhances the relevance and precision of the answers provided and expands the applicability of Q&A systems across various industries and information-rich tasks.
We’ve explored the benefits of RAG for question-answering systems and shown how to implement this approach using Python and OpenAI.
At DjangoStars, we leverage advanced technology to tackle complex software challenges. Our work on the Illumidesk project demonstrates our capability to enhance educational platforms by redesigning their architecture and integrating sophisticated AI features, thereby improving scalability and functionality.
DjangoStars is here to assist if you aim to enhance your digital solutions or create an artificial intelligence poc. Contact us for expert consultations and customized ai and ml development services to ensure your project’s success.
How can a QA process with RAG and OpenAI be enhanced in my system?
- RAG improves question-answering systems by using external information to provide more accurate and context-aware answers, combining retrieval and generative processes.
What advantages do AI integrations offer to digital platforms?
- Integrating AI can automate key processes, enhance user interaction, and enable personalized experiences, significantly improving efficiency and engagement.
Can you transform an existing digital platform to improve scalability?
- Yes, we can update existing platforms to enhance their scalability and functionality, ensuring they can handle larger data volumes and more users efficiently.
What is the typical timeframe for implementing RAG in a system?
- Implementing RAG generally includes a planning and development phase. Depending on their complexity and existing infrastructure, projects can see initial results within a few months.
How do you tailor AI solutions to different industry needs?
- We customize AI solutions by closely analyzing each industry's type, challenges, and requirements to ensure that the technology aligns perfectly with the business goals and operational needs.
Hire experienced developers to build your next project with DjangoStars









