Implementing Third-party API Layers in Fintech Applications


Nowadays, fintech products are everywhere. They visibly or invisibly improve our lives and have made getting loans, mortgages, and other banking services easier and more accessible than ever. This industry boom has initiated a dramatic burst of new startups on the market (e.g, mortgage startups). The stakes are high, and the competition is tough. In competing for clients, companies are inventing more and more sophisticated features, making products more user-oriented, or presenting ever more attractive offers.
But all these neat features won’t mean a thing if the real product works slowly or is clumsy and hard to maintain. Drawing on our 10 years of experience in fintech software development services (with at least 5 of them spent as financial software development company), in this post we’ll share our expertise on how to ensure good application performance by creating well-thought software architecture that implements third-party services via an API layer.
Fintech Applications Primer: Why Third-party APIs are Key
A vast majority of financial applications rely on third-party data and integration of third-party data providers is important stage of the financial app development process. Third-party services provide the application with features which, if they had to be developed from scratch, might require a significant — and excessively long for some lending startups — amount of time. In particular, data received from the third-party API for the fintech app is used to process market offers, analyze the user’s credit score, evaluate property, reveal fraud, or even connect the user’s banking info to their profile. For example, open banking services share data to ensure quicker and easier access to financial services. In sme lending solutions, this is a key part of the business logic, since users typically provide about 15% of the data needed for service delivery.
Using common rules, third-party services are implemented in the product by simple fintech APIs integration. It’s not a problem if there are just a few of them, but when the product is complemented with dozens of such services, fintech app integration and its architecture arrangement may be quite difficult. This is when the API layer can connect third-party services with the product.
Now let’s dig deeper into why our web development company uses a third-party API layer, how they are built, and the advantages they offer in terms of managing complex ecosystems in an elegant way.
Why Use Separate Business and Data Layers in Fintech?
Let’s start with the basics. Why would you even need to separate the business and data layers? By the business layer, I mean business logic. Here, I’ll demonstrate solutions using an example of an online mortgage platform, but it can be applied to any fintech solution that has more than a few integrations with third-party services.
Given that our example platform is directly connected to finance, we must include a lot of verifications, including fraud prevention. Only after all the checks are passed can funds be transferred to mortgage lenders. As you might guess, the data for these checks are supported by the third-party services.
To make it clear, our platform consists of two integral parts — the business one, and the data one. The first is the layer the user interacts with. The data layer is behind the business part and makes it work. It includes third-party integrations that are responsible for providing the data concerning security, fraud recognition, market offers, analysis and other vital services.
The following example will illustrate how this works in practice. A simple lending rule like minimum-age verification (that the customer isn’t less than 21 years old) can be realized by the client while they are filling in their personal data, or by validating this data on the server side. But for the business layer, this rule looks like the function that initially accepts the user’s age argument and results in a boolean value: whether the rule is passed or not.
The lending business may include hundreds of such rules, and the major part of them strongly depends on third-party data providers. The problem is that these services provide data in different formats which may not always be recognized by the mortgage platform’s business layer. As a result, received data must be converted from the external format to the internal one. For example, `Y`/`N` from the third-party fintech API provider must be translated into the boolean `true`/`false` in order to be processed by the business layer.
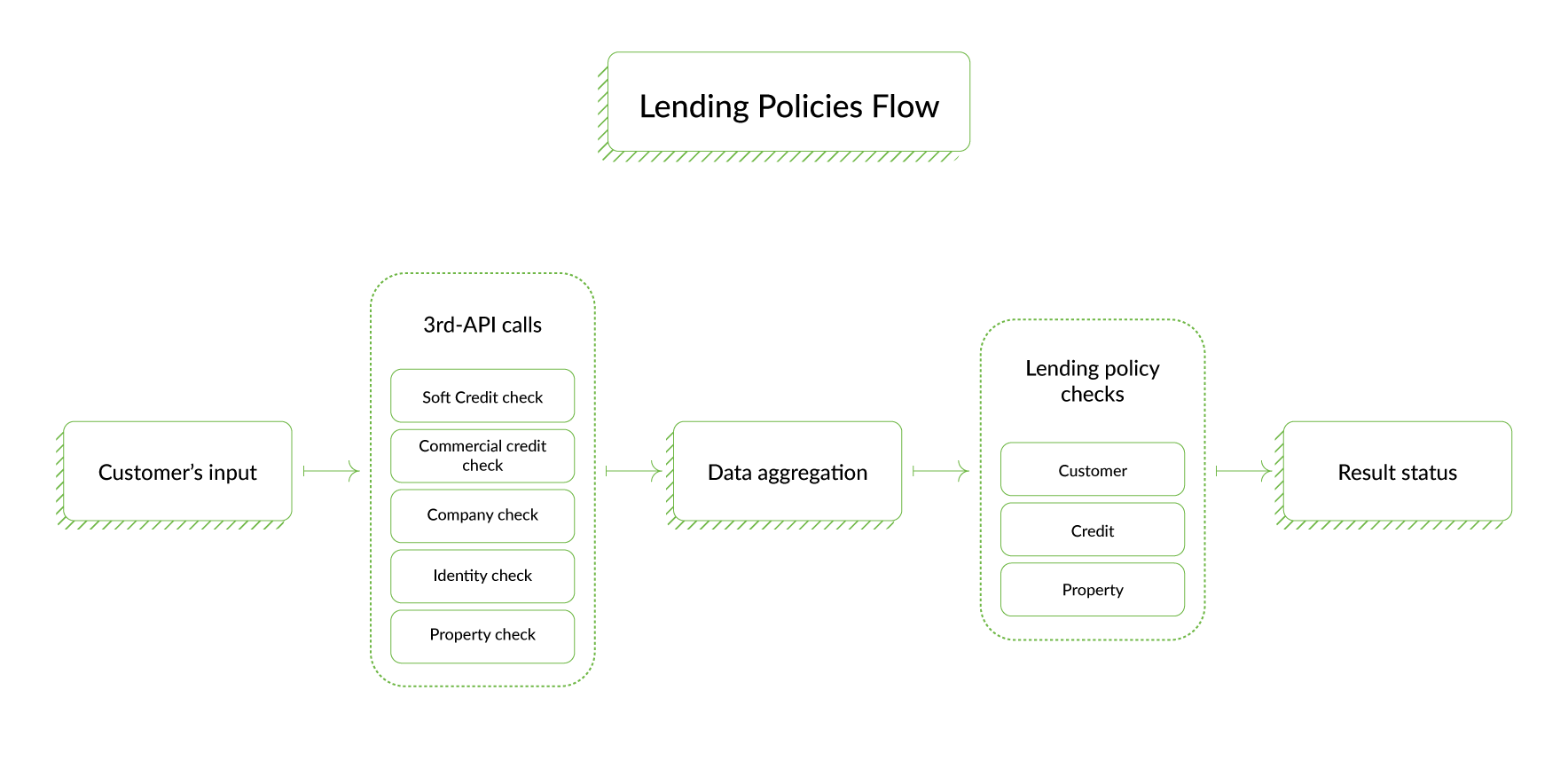
To create a simple verification mechanism to gauge the user’s financial solvency, property quality and other lending criteria, it is necessary to work with normalized and clear data. To ensure smooth performance, where and in what format this data comes from should not be problematic for the business part. Given the fact that it’s necessary to integrate numerous providers in order to receive all the data we need, there is merit in separating them in the particular component known as 3rd-API component. This component should be carried into separate services or projects that will receive info from the user and return formatted data necessary for the lending rules (for the business layer). Thus, to make the process flow smoothly and ensure that all the data will be properly formatted and properly, we separate the business rules from the process of getting data for these rules.
Advantages of Third-party API Layer Implementation
To sum up the above, in our online mortgage platform that uses data from numerous third-party services to properly process information received from the user, we used a third API layer as a proxy between the business layer and third parties. Such an approach ensures a clear and structured service architecture that is easily understandable and manageable. Let’s take a closer look at the advantages this separation provides.
- Elegant and well-thought-out software architecture
- More complete QA coverage
- Easy switching/adding 3rd-party API providers for fintech apps
Elegant and well-thought-out fintech software architecture
Well-thought-out and logically structured product architecture allows you not only to make implementations easily and effectively maintain the service. It also means that the code is easily understandable, the connections between the different components are logical, and that if the product is passed to another development team, they will be able to work with it easily. Even separate teams could work on business and third-party proxy layers. The third API component becomes an aggregated third-party provider for the business component. If you need high confidence in the customer’s taxable income for a lending rule, where and how to get it is a job for a third-API component.
To be clear, paying attention to product architecture is not a “must” in the development process. Sometimes it may take additional development time, and due to that may appear as an excessive effort. But spending a bit more time on architecture structuring at the pre-development stage will save much more time at the development and post-release stage, when product maintenance may require the addition of some components. Well-structured architecture allows you to do it easily and in little time. Although someone may deem a good product architecture a luxury in the development process, we consider it a necessity that will ensure smoothly running product.
More complete QA coverage
By using a third API gateway, it’s possible to create the most complete testing sandbox you’ll ever need. Usually, to test whether the system receives and gives data properly and in the proper format, the tests cover the third-party integration from which this data is received. However, sometimes tests need to check data that a third-party API simply can’t provide due to the limitations of the sandbox.
For example, let’s say we have to check whether the roof of the property to be lent is not thatched. In such case, we create a mock third-party service to test an environment like that one and, with the help of the third API layer, we can easily add mock providers to ensure full test coverage. We have just switched from one property valuation provider to another, but haven’t changed the business flow and logic at all.
Easy switching/adding third-party providers
The most practical advantage of using a third layer for APIs is that by keeping live data and mock inputs separate for testing, you can switch/add providers without touching the business logic.
Thus, you can easily switch between several providers, depending on each separate situation, without affecting the business logic. Thanks to the third-party API layer, the business layer will receive the data in a proper format, irrespective of the type of provider. This means that for less-complex requests you may use providers with more limited volumes of data, but which are cheaper. And if only the request is too complex for a cheap provider, the system will automatically switch to a better one. This allows the system to allocate resources rationally.
How We Build the third-API Architecture
Here’s how you standardize all external vendor data formats using the Lending Rules.
To verify a person’s existence and credit history, it is enough to know their name, date of birth, and residential address. For this purpose, it may be enough to get the user’s selfie and an identity document.
Different web protocols can be used to interact with third-party providers. These include SOAP, REST, XML-RPS and others. As well, different types of data access protocols – such as WASP, API tokens, and others – can be implemented. Third-party providers typically return data in a format that differs from the format needed for the project, so you need to standardize these formats to enable the business layer to process it.
For example, the key SPI46 from the third-party vendor stands for the user’s taxable income for the last 12 months. To the third-API component, the strange name is converted to gross_annual_income field, with a float type. Even more, the third-API gateway component returns this data in JSON, but initially was received from the third-party vendor in XML format.
If the one data provider changes to another, the business logic should not be affected. The function of checking the taxable income of the user must remain the same as it was with the previous provider. In this case, though, the data provider changes, but the third-API gateway service itself retains the same interface. It receives and returns the same data as before. The field in which the new data provider provides information about a person’s income for the last year is called PersonPreviousYearIncome, but the third-party API itself still gives the information in the field gross_annual_income, and still in JSON.
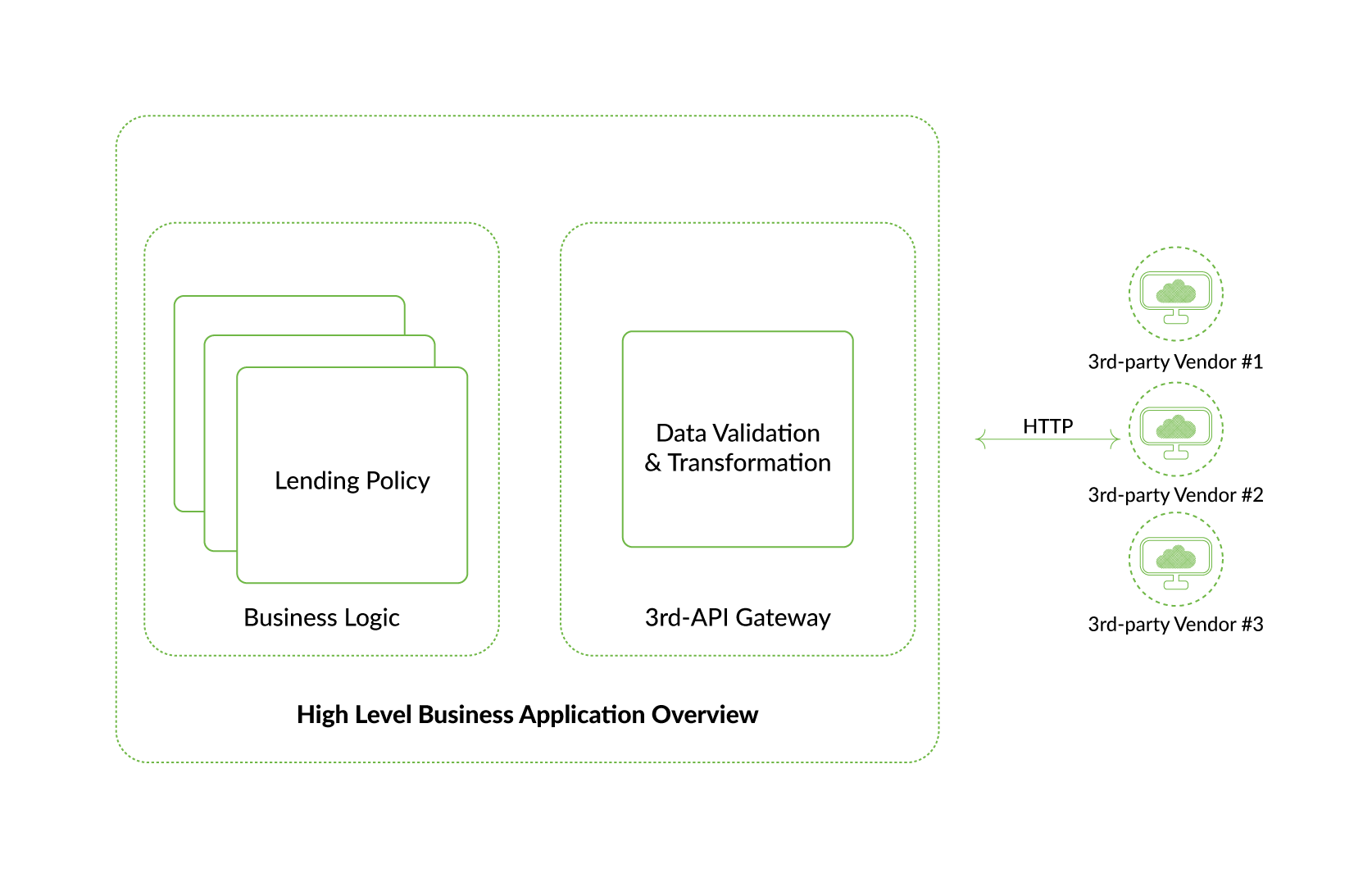
Thus, the third-API gateway serves as a layer for communication with the third-party providers. It is able to work with different data providers, preserves the same interface, and normalizes and recasts data to the type used internally.
Use-cases for Backend-selectors and 3rd-API Architecture
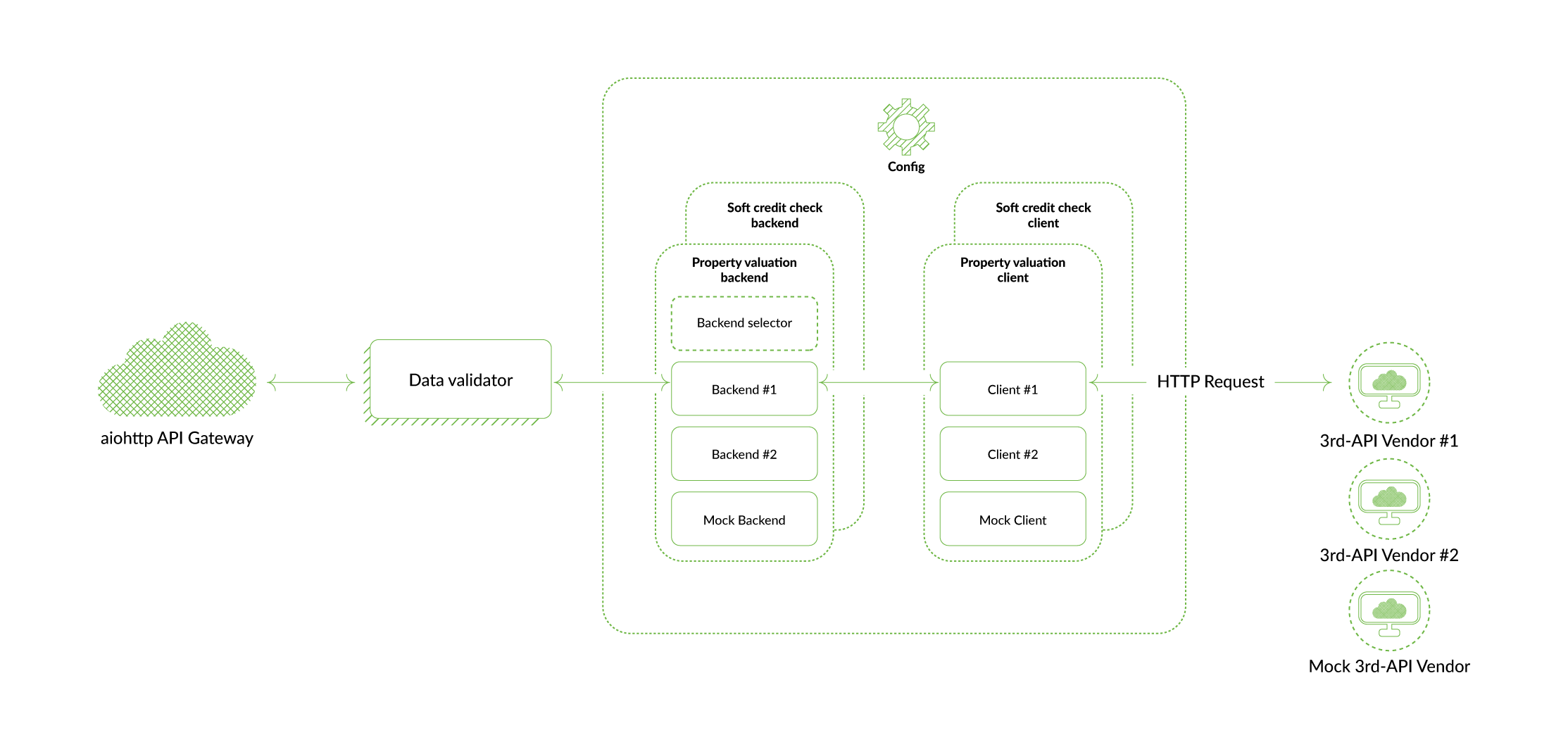
In this section, I’ll demonstrate how our software development team uses the above solution in our online mortgage platform. So, we have a third-API gateway that can communicate with third-party integrations and has a stable and fixed interface. To make it work as required, it is necessary to write a backend (provider) selector that will work with different data providers, depending on the environment.
Use case #1. Let’s assume we have a credit rule for real estate: verify that the roof of the building is not made of straw. Given the limitations of the testing sandbox of a default real estate appraiser, it will be difficult (or even impossible, in this environment) to find such a property in London. Thus, in the test environment you can switch to another provider – for example, to the data that will be specified by the QA team for the property of interest. This type of provider can be called a “mock provider”. The service that is responsible for business logic receives data from the third-API gateway, runs a credit rule, and testers (QA) can make sure that the user whose property has such a roof won’t be able to move further along the flow.
Use case #2. There are a lot of data is based on property addresses. Let’s assume the customer interacts with the residential or property address input. The backend turns to the third-API gateway which, via search keywords, begins to query all of the data providers for the address search described in the application. The response of the first one is returned by a gateway to the main application, and from the backend to the client side. Thus, for the main application, it makes no difference what kind of integration the address details have been obtained from. The application just needs to know those details, and that’s it.
Conclusion: When to Use this Approach and What to Pay Attention to
The above solution significantly simplifies the application structure, and makes it clear and concise. To be clear, it won’t be the end of the world if the architecture of your application remains messy (for some time). For example, if your aim is to make an MVP just to test your idea, a messy structure is okay. But if you’re planning to release the application to the market, you’d better pay attention to its architecture and structure. Otherwise, in the future it may be quite hard to scale the product or add new features to it.
Also, you should note that you need to remember to keep an up to date third-API client on the business side with third-API proxy component layers. If the field name from the business layer changes, the third-API layer should also change its API. Both the business side and third-API components should be synced with each other (if it is related to the field names).
An API layer is a savior when you’re building API for a financial app that has numerous integrations with third-party services. The payer can be used in fintech and other areas where application business logic is the keystone.
If you need assistance implementing a third-party API layer for a financial app or for insurance software development, contact the DjangoStars team.
- What is 3rd party API integration?
- 3rd-party API integration refers to connecting an application or software system to a third-party application programming interface (API) in order to access its functionality or data. This helps 3rd-party services provide the application with features which, if they had to be developed from scratch, might take a significant amount of time.
- How does integrating third-party API work in Django?
- Django makes it easier to integrate 3rd-party APIs. It has many libraries and packages that help interact with various APIs, as well as convenient tools for creating APIs. For example, the Django Rest Framework (DRF) library helps quickly create RESTful APIs and easily integrate them into projects. DRF also provides many tools for authorization, authentication, and restricting API access. In addition, Django projects can use the urllib Python module, which allows sending HTTP requests and receiving responses from third-party APIs.
- What APIs for fintech lenders are the best?
- Check out the article that lists some examples of the best data-providing services for fintech products from DjangoStars' practice. However, there is no definitive answer to what APIs for fintech lenders are the best, as it depends on the specific needs and requirements of each project. It's essential for fintech lenders to carefully evaluate the features, security, and pricing of each API before integrating it into their platform.
- What are the benefits of 3rd party API layer implementation for fintech architecture?
In a fintech platform that uses data from numerous 3rd-party services, we can use a third API layer as a proxy between the business layer and 3rd-parties. Such an approach ensures a clear and structured service architecture that is easily understandable and manageable. Also, the advantages this separation provides include
- elegant and well-thought-out software architecture,
- more complete QA coverage, and
- easy switching/adding 3rd-party providers.
- How long does it take to integrate and configure the API for a banking or fintech app?
- The time it takes depends on various factors as the API's complexity, the availability of documentation and resources, the skills and experience of the development team, and the extent of customization required. Typically, it can take anywhere from a few days to a few weeks to fully integrate and configure an API for a banking or fintech app. It's important to ensure that the integration is done carefully and thoroughly to avoid any potential security risks or errors in functionality.
Hire experienced developers to build your next project with DjangoStars








